


One of the main performance problems of Transactional Relational Databases (OLTP) occurs when including Analytical Workloads (OLAP) with queries that recover a large amount of information. In many cases for purposes other than the application itself such as BI systems. This type of access has a considerable impact on performance for several reasons, such as the capacity of the database infrastructure tailored to the transactional use of the application, or the data model design optimised for the type of access, more atomic, of a transactional system rather than an analytical one.
In order to solve these problems Amazon Aurora has two features that we will study, Auto Scaling of read-only replicas (Readers) and Custom Endpoints dedicated to specific instances.
Readers Auto Scaling #
Amazon Aurora Auto Scaling allows you to automatically adjust the number of Read Replicas of an Amazon Aurora RDS cluster. This mainly allows you to adjust the platform’s capacity for unpredictable workloads.
Amazon Aurora Auto Scaling allows you to define a maximum and a minimum of instances the same way Amazon EC2 Auto Scaling groups do. However, as a difference, instead of defining a scale-out value and a scale-in value for the Auto Scaling metric, only one target value is defined, which serves as an upper threshold value. Amazon Aurora Auto Scaling automatically defines the lower value.
How it works #
The operation of Amazon Aurora Auto Scaling is based on two different components that need to be defined.
Scalable target #
It is responsible for defining the maximum and minimum capacity of the auto scale. Only one scalable target can exist per Amazon Aurora cluster. The capacity defined in the scalable target affects everything, that is, the total number of reader instances is taken into account whether these are self managed or auto scaling managed.
Some examples:
Let’s assume we have the following capacity.
-
Min capacity: 1
-
Max capacity: 4
The cluster shown below would have the ability to grow only 2 more instances since the total number of Reader instances cannot exceed 4 units. In the same way you cannot have less than 1 Reader instance, however, when you have a self managed Reader instance, you could eventually have 0 Reader instances managed by Auto Scaling.
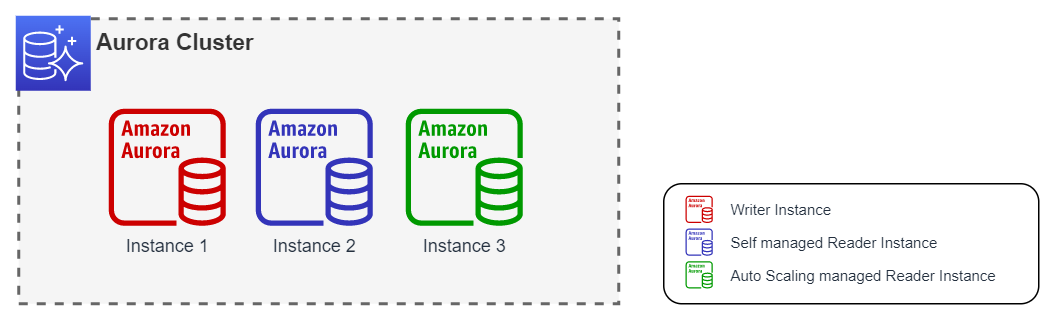
In the next case, the cluster would have the ability to increase 1 more instance until reaching the maximum. For the minimum, you could delete all reader instances except 1.
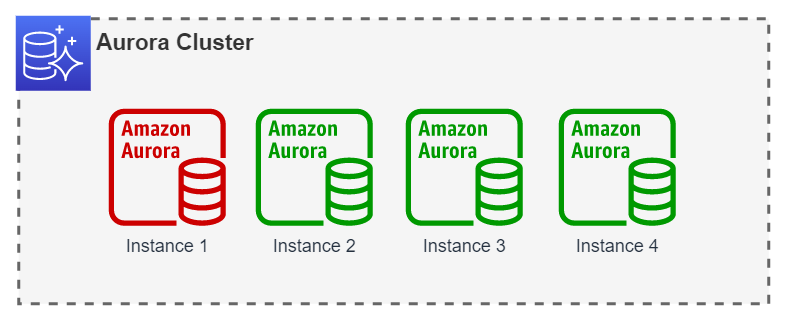
In this last example, the Auto Scaling maximum capacity has already been reached, in fact, it has been exceeded by having 5 self managed instances already created. The Auto Scaling limit does not influence the maximum limit of self managed Reader instances in an Amazon Aurora cluster, however the maximum limit allowed by Amazon Aurora is 15. This limit includes both kind of Reader instances, self managed or Auto Scaling managed.
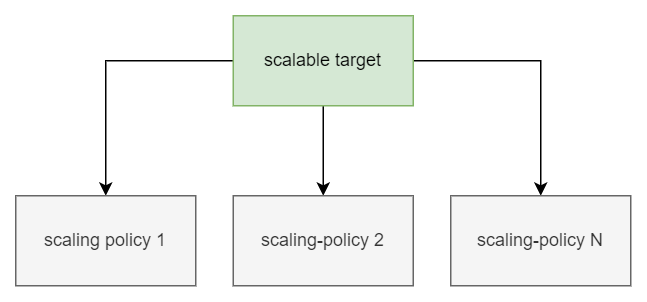
Scaling-policy #
It is responsible for defining the metric to be monitored to control Auto Scaling, and the target value to be achieved in the cluster.
There may be several scaling policies associated with a scalable target, although it is usual to define only one.
Metrics can be of two types, predefined or custom.
The predefined metrics you can choose are two:
-
RDSReaderAverageCPUUtilization: It is the average value of the CPUUtilization metric in CloudWatch among all Aurora Replicas in the Amazon Aurora cluster.
-
RDSReaderAverageDatabaseConnections: It is the average value of the DatabaseConnections metric in CloudWatch among all Aurora Replicas in the Aurora cluster.
For custom metrics you can choose any metric that makes sense, as long as you take into account the status of all the read replicas. A limitation of this is for example the impossibility of choosing a metric that affects only a subset of read replica instances. This is due to how dimensions are organised in CloudWatch for RDS/Aurora. In an Amazon Aurora cluster, the only valid dimensions are ClusterId, Role (Writer or Reader) or only ClusterId.
Auto Scaling cluster failover #
To avoid failover on an Auto Scaling managed instance, AWS assigns the lowest priority (tier-15) to this instance type. This way, self managed reader instances (usually with tier-1 priority) will have preference as a candidate in the event of a failover. However, if there are no self managed readers in the cluster, any of the Auto Scaling managed reader instances would be marked as a candidate in case of failover.
Some examples:
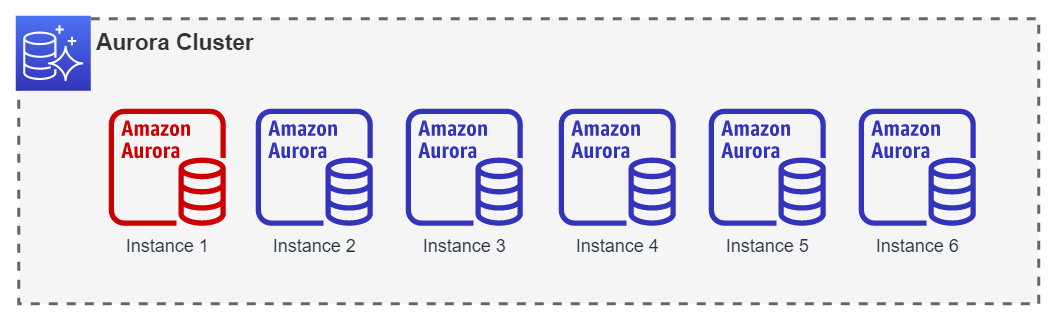
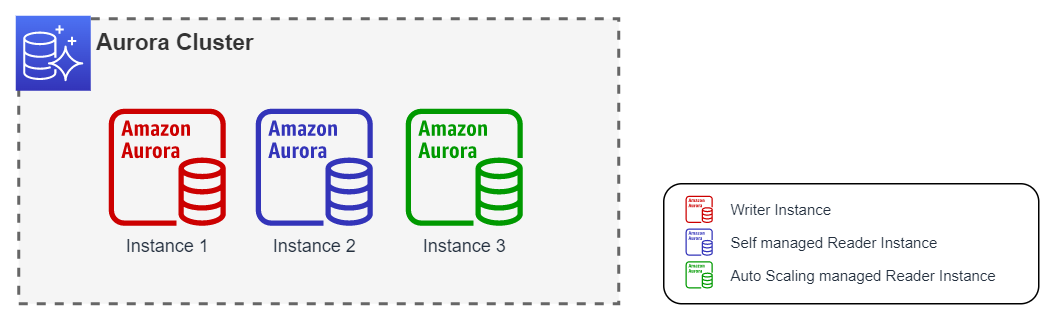
In this case, the failover will always be performed between instance 1 and instance 2.
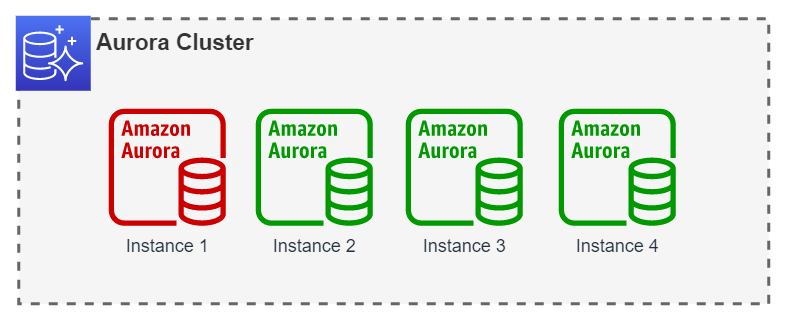
In this case, the failover will be performed to any of the reader instances (2, 3 or 4) however, a second failover will always return to instance 1.
Implementation #
You can deploy the Auto Scale configuration from both the AWS console and AWS CLI. From the AWS console, it is only possible to use predefined metrics. The creation of both the scalable target and the scaling policy is done in a single step, making it very simple to configure.
From AWS CLI, it is necessary to define the scalable target and the scaling policy individually, it is also necessary to define the configuration of the metric in a JSON that is used as an input in the creation of the scaling policy. This applies whether the metric is predefined or custom.
Implementation details can be found at Using Amazon Aurora Auto Scaling with Aurora replicas.
Limitations and recommendations #
Although some of the limitations have already been discussed in previous sections, the following limitations and recommendations of Amazon Aurora Autoscaling need to be taken into consideration.
-
Do not set Min capacity = 0, especially in those clusters that do not have self managed Reader instances. If a cluster runs out of Reader instances, the Auto Scaling stops working as the rules running the scaling are left in Insufficient Data state.
-
If all instances of the cluster are not in the Available state, the Auto Scaling actions are not executed.
-
The target value of the metric defines the maximum limit of the Auto Scale, that is, the one that once exceeded causes a scale-out. The minimum value is auto calculated by AWS and is always 10% less than the maximum value. When the metric is below this minimum value a scale-in occurs.
-
The time period that the metric has to be above or below the maximum or minimum value respectively is fixed. The maximum value is 5 minutes. The minimum value is 15 minutes.
-
The increment of instances in the scale-out is variable, AWS determines the number of instances necessary to reach the target value, always within the maximum and minimum limits, and creates them at the same time.
-
The scale-in instance decrement is always fixed with a rate of 1 instance at a time.
-
If there are no self managed Reader instances, the cluster failover is performed on one of the Auto Scaling managed instances.
Custom Endpoints #
In an Amazon Aurora cluster, the use of endpoints allows you to map each connection with a set of instances. By default, each Amazon Aurora cluster includes 2 predefined endpoints.
-
Writer Endpoint: Points to the instance that currently has the Writer role in the cluster.
-
Reader Endpoint: Points to the instance or instances that currently have the Reader role in the cluster.
In addition AWS allows the creation of custom endpoints in which you can specify a discrete set of instances to include.
How it works #
Custom Endpoints can be of three types. READER, WRITER or ANY. Each type can only contain instances that have the corresponding role.
It is important to know that when changes occur in the configuration of Custom Endpoints, the active connections on the instances are not interrupted or altered. Therefore, changes that occur in an endpoint, for example when an instance is added or removed, only have an effect on new connections that are made from that moment.
A Custom Endpoint can be defined by an inclusion list or an exclusion list. You can only have one list type for each Custom Endpoint. Instances included in such lists are included or excluded from the endpoint regardless of whether the role of the instance matches the custom endpoint type.
When an inclusion list is defined (whitelist), only those instances indicated in it are included in the endpoint. Any new instances created since then will also remain outside the endpoint.
However, for exclusion lists (blacklist) only those instances included in the list will be excluded from the endpoint. Any other unspecified instances as well as instances that are created from that moment on will be included in the endpoint.
For more information on using Custom Endpoints see Amazon Aurora connection management.
Simultaneous use of Readers Auto Scaling and Custom Endpoints #
As we can see in the section on Readers Auto Scaling, although through custom endpoints it is possible to create a subset of read instances that are accessed only for a specific purpose and, this way, do not affect the rest of instances in the cluster, it is not possible to configure Auto Scaling metrics that measure only a subset of instances. These metrics will always measure all instances with a READER role. Any massive access to only one of the instances will have an effect on the average of the whole set and therefore influence the scaling of the cluster.
Therefore, the final conclusion is that the use of both technologies combined does not allow to solve the problem that has been initially raised.
Recommended configuration #
Based on what has already been seen in previous sections, the following standard configuration is recommended. It will need to be customised to the specific needs of the Amazon Aurora cluster where it is to be applied.
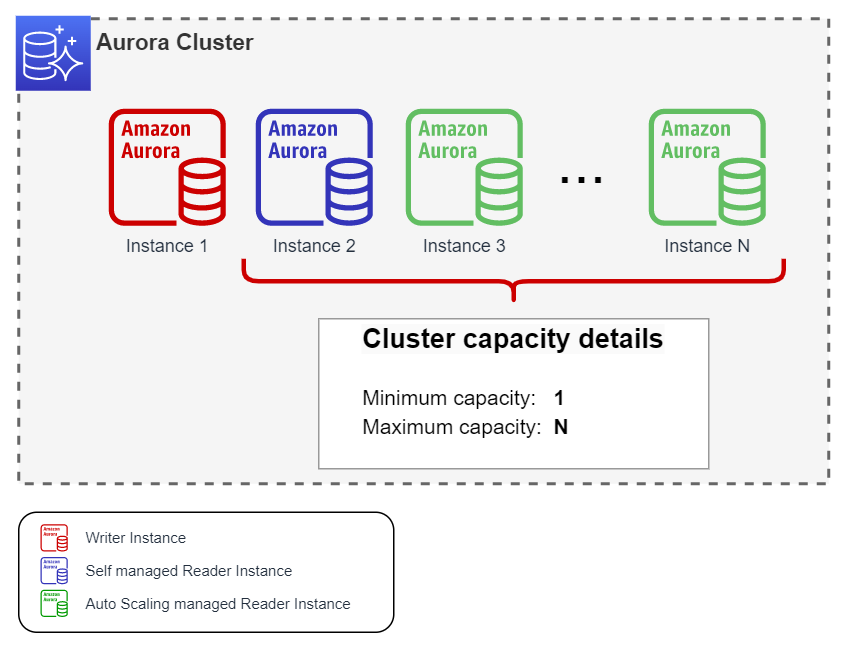
As a rule of thumb for this configuration, it is recommended to have a Writer instance and a Reader self managed instance of the same type and size. It is recommended to leave Failover priority parameter at its default value which is tier-1, thus ensuring that the failover of the cluster will always be performed between these two instances. The number of instances managed by Auto Scaling will be variable, between zero and the maximum number that is specified in the configuration depending on the read load in the cluster.
It is recommended to apply the configuration in the AWS console, although it is also possible to do it in AWS CLI as described in Adding a scaling policy to an Aurora DB cluster.
These are the recommended parameters:
Policy details #
-
Target metric: It is recommended to choose any of the predefined metrics based on the cluster needs. These are Average CPU utilization of Aurora Replicas or Average connections of Aurora Replicas.
-
Target value: The target value to keep for the selected Target metric.
Cluster capacity details #
- Minimum capacity: It is recommended to always use the value 1.
Maximum capacity: Indicate the maximum number of instances desired according to the needs of the cluster. The upper limit is 15.
Conclusion #
In conclusion, this article highlights the performance challenges of integrating Analytical Workloads with Transactional Relational Databases and introduce key features of Amazon Aurora: Auto Scaling of read-only replicas and Custom Endpoints.The detailed examination of Amazon Aurora Auto Scaling, including failover strategies and limitations, was discussed. The article also explored Custom Endpoints and their types. However, the simultaneous use of Readers Auto Scaling and Custom Endpoints was found insufficient to fully address the challenges of integrating OLAP workloads with OLTP databases.
References #
Using Amazon Aurora Auto Scaling with Aurora replicas